Secure Multi Tenancy
The Challenge: Securely sharing expensive GPU clusters across different internal teams or external clients without data cross-talk.
The Solution: Hedgehog brings hyperscaler-grade logical isolation directly to bare metal. Operators can instantly spin up fully isolated Virtual Private Clouds (VPCs) with strict boundary enforcement, allowing you to partition and monetize your AI services securely.
- Provides the core abstractions modern teams need
- Enforces strict multi-tenant isolation across physical clusters

Network Performance
The Challenge: AI workloads demand two distinct network profiles: massive, lossless bandwidth to synchronize distributed training jobs without stalling GPUs, and predictable, ultra-low latency for high-concurrency inference serving.
The Solution: Hedgehog delivers an automated underlay and overlay network dynamically optimized for these unique traffic flows. By deploying validated configurations on open hardware, our fabric eliminates dropped packets to slash training time-to-completion, while ensuring the high-speed, reliable data delivery required to maximize your inference tokens per second.
- Lossless, high-throughput underlay and overlay automation
- Permanent hardware independence and vendor choice

Network Availability
The Challenge: Brittle configurations and manual updates lead to downtime and broken training runs.
The Solution: The continuous reconciliation of our Fabric Agents guarantees that the network state remains exactly as intended. If a state drifts or a link fails, the fabric automatically reroutes and heals without manual intervention.
- Native management via the Kubernetes API and CRDs
- Empowers platform teams to control networking within existing workflows
Lifecycle Management
The Challenge: Racking, provisioning, and updating network hardware manually takes months and requires specialized engineers.
The Solution: Zero Touch Lifecycle Management (ZTLM) accelerates your time to GPU value. Our software automatically discovers bare-metal hardware, provisions the OS, and pushes validated configurations the moment a switch is plugged in—taking you from rack to ready in hours.
- Automated device discovery and declarative provisioning
- Free up engineering resources with hitless lifecycle maintenance

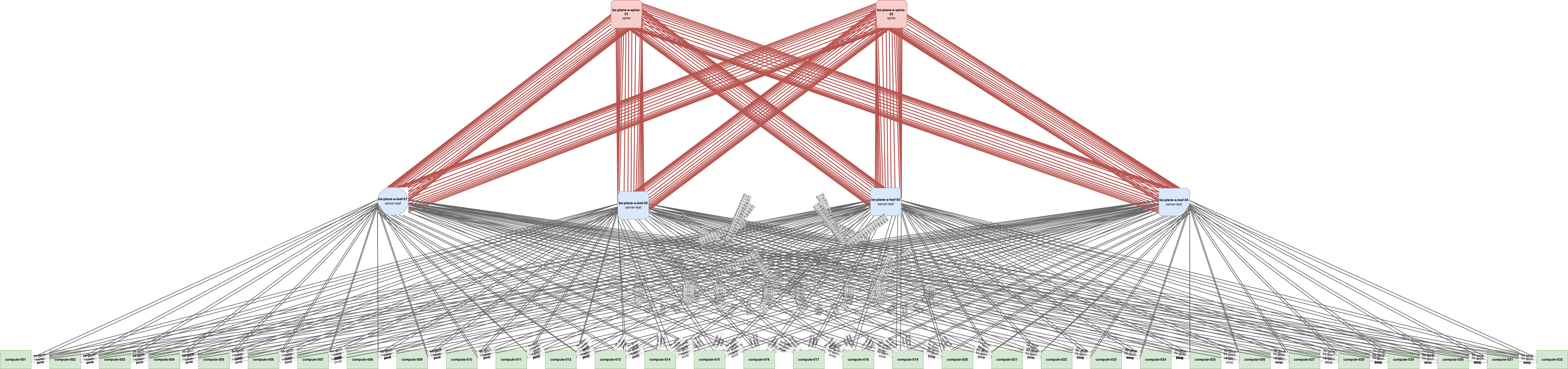
Scales to Fit
The Challenge: Network architectures that require massive upfront over-provisioning or require forklift upgrades to grow.
The Solution: Hedgehog supports highly flexible, automated spine-leaf topologies. Start with the capacity you need today and scale out your physical topology non-disruptively as your AI cluster grows
- High-bandwidth external routing and simplified BGP peering
- Unifies distributed AI workloads without traffic choke points
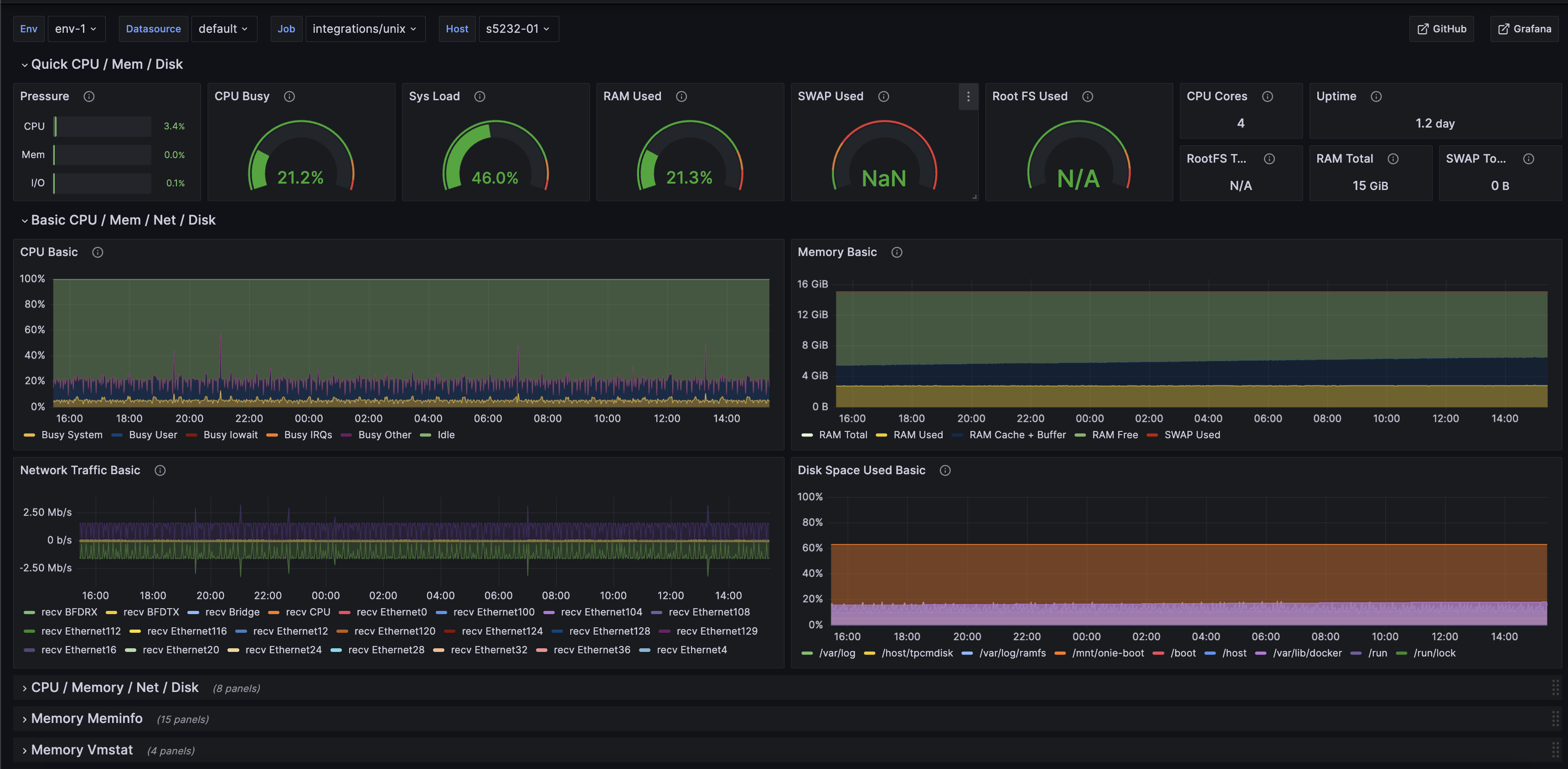
Observability
The Challenge: Traditional monitoring tools sample traffic too slowly to catch the micro-bursts that stall GPU workloads.
The Solution: Deep, real-time telemetry mapped directly to cluster performance. Hedgehog exposes granular flow and queue-depth visibility, streaming natively into Prometheus and Grafana to proactively detect and resolve packet drops.
- Real-time visibility into micro-bursts and queue depths
- Full automation ensures clusters live up to their absolute potential
Firewall & NAT
The Challenge: Securing proprietary models and training data at line rate without degrading cluster performance.
The Solution: Integrated, stateful NAT and firewalling at the Gateway layer. Enforce zero-trust micro-segmentation and robust security policies directly within the fabric's flow, keeping your multi-tenant boundaries locked down.
- Policy-driven security enforcement within the fabric
- Strict tenant isolation guards against internal and external cross-talk

Data Center Interconnect
The Challenge: Distributed AI training requires bridging "AI islands" to external data lakes and public clouds.
The Solution: Unify your distributed workloads. We simplify BGP peering and Data Center Interconnect (DCI) routing, providing high-bandwidth external ingress and egress to keep your training pipelines fed without choke points.
-
Predictable Costs for High-Volume Data Transfer
-
Hedgehog never charge ingress or egress fees