
 Marc Austin
Marc Austin
1 min read
Enterprise AI Models: How Hardware Advances Are Reshaping the Self-Hosting Calculus
Cohere's recent $6.8 billion valuation signals something interesting about enterprise AI preferences, but not quite what you might expect. While...
DeepSeek AI proved that optimized reinforcement learning and mixture-of-experts techniques yield dramatically lower cost and barriers to entry or AI training.
AI researchers and new AI industry entrants are now thinking outside the box of Nvidia orthodoxy, experimenting with platforms like AMD's Instinct™ MI300X accelerators.
Over the short term, this will drive more demand for AI training on high-performance back-end GPU networks. One of our customers, a major GPU cloud provider, is already seeing this trend emerge.
Over the medium and long term, more enterprises will turn to Hedgehog for AI networks that deliver real-time AI inference from AI infrastructure at the data edge.
DeepSeek AI is a Chinese startup associated with High-Flyer, an $8 billion Chinese hedge fund, who offers a large language model with artificial intelligence quality comparable to ChatGPT as measured by common generative AI benchmarks. DeepSeek's AI Assistant, powered by DeepSeek-V3, has overtaken rival ChatGPT to become the top-rated free application available on Apple's App Store in the United States.
OpenAI’s GPT-4 cost about $78 million to train in 2024 while Google’s Gemini Ultra cost over $190 million for compute. Meta's Llama 2, a similar model, required approximately 1,720,320 GPU hours to train. According to Dario Amodei, the CEO of Anthropic, training AI models can cost anywhere from $100 million at the lower end to $1 billion or more for more complex models. Amodei estimated that by 2025, the cost of developing competitive AI models could reach $10 billion.
Tech giants to date have been willing to invest vast sums to win the game of thrones for AI dominance and the de-facto portal for access to all human knowledge. Western tech giants, venture capital, private equity and hedge funds invested over $25.2 billion in generative AI last year. The United States and its allies were confident that they were well ahead of China in the AI arms race, until DeepSeek rocked the boat in late January of 2025. Donald Trump announced “the largest AI infrastructure project, by far, in history” with Softbank, OpenAI and Oracle investing over $500 billion in Stargate. Then a Chinese company threw egg in America’s face over the weekend. Come Monday Marc Andreesen tweeted “Deepseek R1 is AI's Sputnik moment” on social media, sending stock markets into a frenzy of fear, uncertainty and doubt. Nvidia's share price experienced an unprecedented decline, falling 17% and erasing nearly $600 billion in market value.
DeepSeek AI has proven that it can train a large language model at a fraction of the cost of big tech LLM providers like OpenAI’s ChatGPT.
DeepSeek trained their DeepSeek-V3 and DeepSeek-R1 models in China with GPUs that were available to them despite GPU export restrictions enforced by the United States government. DeepSeek claims they trained DeepSeek-V3 using a cluster of 2,048 Nvidia H800 GPUs. H800 GPUs cost 10%-30% less than H100 GPUs with more limited computing power, but DeepSeek cut their training time significantly by optimizing their frameworks and software. The capital investment for these GPUs was about $60 million. The final training run cost about $6 million. DeepSeek AI trained their AI models for 3 percent to 5 percent of what US tech companies spent to do the same thing. This lower cost approach was a serious wake-up call for AI researchers and investors.
They didn’t just throw more hardware at the problem. DeepSeek optimized their AI training approach and their AI software optimization to work around GPU hardware export restrictions. DeepSeek AI researchers used reinforcement learning and mixture-of-experts techniques to train their models more efficiently with limited resources.
The net result is that AI inference is now cheaper inference. DeepSeek-R1 set the bar at USD $1 per million tokens for a model with an Artificial Intelligence index of 60. OpenAI o3-mini now has a slightly higher quality index of 63, but costs nearly twice as much at USD $1.90 per million tokens. This example illustrates the law of diminishing marginal returns on AI systems. A 5% improvement in model quality is not likely worth 190% more money for an AI tool to the average user.

Om Malik describes this phenomenon well:
“DeepSeek AI has shown that you don’t need the absolute cutting-edge, most expensive AI models for most real-world applications. Instead, what’s required are efficient, well-engineered products that can solve complex problems...
This is not the first time a company has thought differently about infrastructure and figured out a way to do more with less. In the not-so-distant past, Juniper Networks and Google followed the same recipe and changed networking and infrastructure in the process.”
Speaking of changing networking and infrastructure, that is exactly with Hedgehog is doing with AI networking. We make it possible for more players to train low-cost open source generative ai models with large-scale data sets. This means that more enterprises can use their proprietary data sets for fine-tuning open source generative AI models, then combine those fine-tuned models with machine-learning, computer-vision, and other algorithms for application outputs that deliver for more value than chatbots replacing customer service representatives.
The DeepSeek AI event rapidly got data scientists and AI researchers thinking outside the orthodox confines of Nvidia reference architectures. No longer will everyone go to GTC, worship at the alter of Jensen Huang, and pay nearly any price for his latest large-scale AI platform.
More AI researchers are now likely to experiment with other GPUs on alternative platforms. We've seen this with one of our customers who operates a sophisticated AMD-based GPU cloud service. That will create competition in AI infrastructure, which is a good thing for enterprise consumers. If DeepSeek AI can train DeepSeek-R1 on inferior H800 GPUs, why can’t new entrants train on significantly better AMD MI300X GPUs? With 2.4x memory capacity, 1.6x more memory bandwidth, 1.3x more streaming processors, and 2.4x more FP8 TFLOPS compared to H100 and even more compared to H800, it opens the gateway for increasing innovation, diversity and choice for industry consumers.
That trend toward open platforms will accelerate dramatically when AI developers have an abstraction on CUDA that is GPU platform independent. It will be analogous to Sun breaking the Microsoft x86 Visual Basic Monopoly with Java Virtual Machines in the mid 90's. GPU competition means growth for Hedgehog.
This departure from Nvidia orthodoxy extends beyond the GPU. It impacts the AI network, too. No longer will every AI cloud builder turn immediately to Nvidia Infiniband or even Nvidia Spectrum-X. If lower-cost GPUs can train good models, why can’t lower-cost ethernet networks train them, too?
For example, we're currently collaborating with a customer who has built an advanced GPU cloud. Together, we're tuning network performance for training workloads. This collaboration will give AMD an AI network that meets the performance of Nvidia Spectrum-X with a much simpler and easier cloud user experience.
We have been saying for a while that AI workloads will migrate from AI training to AI fine-tuning, and then to AI inference. Lower cost inference will just accelerate that trend with more open-source AI models and more choice for enterprise AI application developers. DeepSeek AI will push more enterprises to get off the sideline and start executing their AI strategies.

More open source models = more enterprise adoption of AI. When enterprises start an AI project they will take open source models from players like DeepSeek AI (or more likely their western alternative), tune with their private data sets on private AI infrastructure, then deploy tuned models to the data edge for inference. That's where Hedgehog is the network for distributed cloud infrastructure and low latency inference.
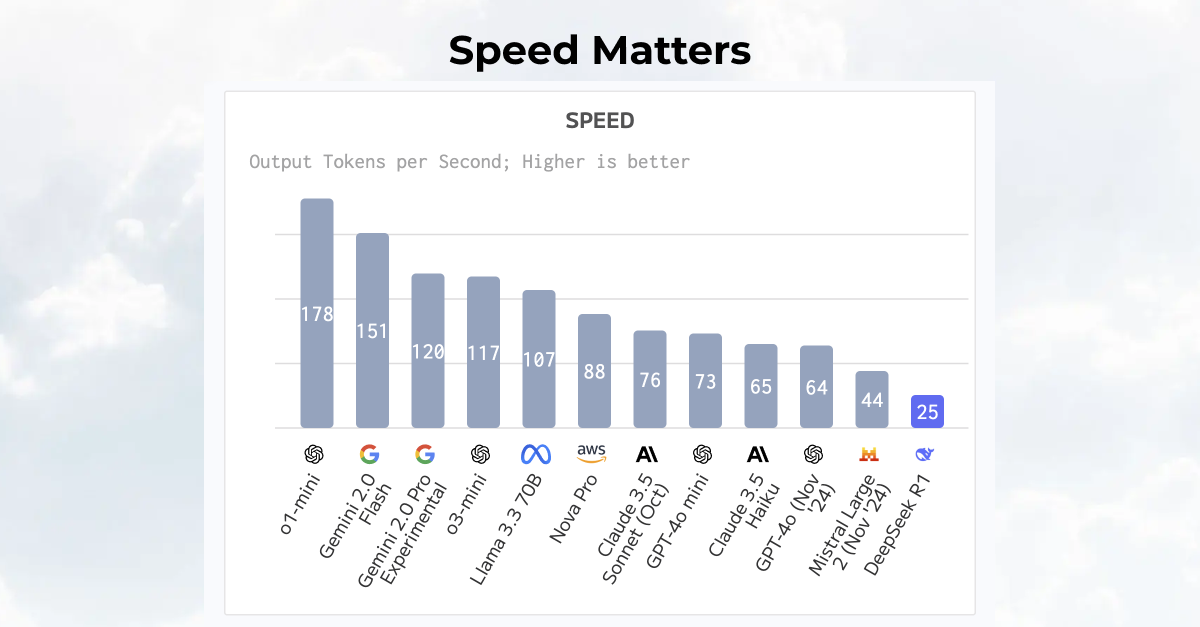
The DeepSeek AI quality to price ratio sounds really compelling, but it is sorely lacking in speed. By this metric, OpenAI’s o3-mini is vastly superior to DeepSeek-R1. o3-mini outputs 117 tokens per second while DeepSeek-R1 ranks last in speed with only 25 tokens per second. Total response time and latency are relatively high as well. Lower latency and faster response times generally mean better user experience and higher customer satisfaction. Everybody wants real-time response. Nobody likes waiting for an AI to respond when another AI gives us instant answers.

So what’s the root-cause of latency, speed and response time. One key variable is the model provider. The location of the provider matters. If the provider is closer to the source of inference data, latency is lower, speed is higher and total response time is faster. In the case of a large language model, the source of inference data is a user prompting a web browser or an API. DeepSeek serves their inference from China on low performance networks, so the distance in longer, speed slower, and total response time greater.
In the case of computer-vision and machine learning models, the source of data is often a machine like an optical camera, laser or another sensor connected to a network. In either case, the closer the infererence model is to the source of data, the faster the response time. For applications like autonomous driving or flying, the response time must occur in milliseconds lest your artificial intelligence crash your car or drone. That's why inference models run in the car or drone, directly next to the source of inference data.
The network matters a LOT for inference speed. Networks that support distributed AI infrastructure, close to the source of inference data reduce latency, increase speed, and improve response times. Optimized network throughput with next-generation high-performance network architectures matter, too. Nvidia does this high-performance AI networking. That’s why AI networking represents almost a third of their total data center revenue. Hedgehog delivers an AI network with comparable performance, but we do it cheaper and more efficiently because we have been driven to innovate by the same necessity that drove DeepSeek AI to optimize their training techniques.
If you are an enterprise considering AI infrastructure for your AI use case, take a look at Hedgehog. We offer a high-performance AI network that delivers fast response times for your users. Because it is based on open-networking standards, it’s a fraction of the price of Nvidia AI networks, and it offers a familiar cloud user experience that you just don’t get with any other AI networking alternative. For more information, visit https://hedgehog.cloud and click the DOWNLOAD button.

1 min read
Cohere's recent $6.8 billion valuation signals something interesting about enterprise AI preferences, but not quite what you might expect. While...

1 min read
Why Traditional Networks Fail AI Workloads The billion-dollar bottleneck hiding in your artificial intelligence infrastructure

1 min read
If you work with AI infrastructure, build applications with large language models, or fine-tune models for your organization, you've probably heard...