
 Marc Austin
Marc Austin
1 min read
The Reliability Math: The Real Cost of Network Disruptions
Hedgehog AI Network Planner: Part 7

Hedgehog AI Network Planner: Part 5
Building a GPU cluster is a one-time capital event. Operating it is an ongoing payroll commitment. The engineers who keep a 1,024-GPU multi-tenant AI cloud running — the SREs paged at 3 AM when NCCL hangs, the network specialists debugging a PFC storm, the automation engineers maintaining Ansible playbooks, the remote hands swapping optics in a rack — are on payroll every month, whether the cluster is busy or idle. Getting the staffing model right has a larger long-term impact on unit economics than almost any procurement decision.
This post answers a specific question: how many people does it actually take to operate a production AI cloud, and how does that number change depending on the network architecture you chose?
The headline finding: a Hedgehog-based AI cloud can be operated by a software engineering team, with no specialized network function. This is not a theoretical claim. It is documented in the published Zipline customer case — where Florian Berchtold, a software engineer at Zipline, runs their private AI training cluster using Hedgehog's Kubernetes-native declarative API with no dedicated NetOps team. The equivalent DIY operator, running Ansible-based network automation, needs 4 specialized NetOps engineers, 4 cluster SREs, 2 network automation engineers, and 2 remote hands — 12 people in total. The Hedgehog operator needs 4.
The dollar gap on payroll is $2.6M annually in favour of Hedgehog. That number matters, but it understates the real value — the incremental EBITDA a Hedgehog-based operator earns versus a DIY operator comes primarily from the operational outcomes the staffing difference enables: faster incident remediation, validated RoCE performance, and hardware-enforced tenant isolation. Those outcomes are captured in the reliability, performance, and security analyses. The operations analysis establishes the staffing model that makes them possible.
Zipline operates a global autonomous drone delivery service. Their drones generate roughly a gigabyte of telemetry per flight, and they train AI models on that data to fly and land deliveries autonomously. Zipline built a private AI cloud on-premises rather than renting from a hyperscaler — citing significant cost efficiencies and governance advantages. Their case, presented at Networking Field Day 38 in July 2025, is the clearest public account available of what it looks like to operate an AI cloud with Hedgehog.
Florian Berchtold, Zipline's Principal Engineer, described the design constraint:
"Florian, a software engineer rather than a network engineer, sought a high-bandwidth networking solution that didn't demand extensive network CLI expertise. Hedgehog provided a Kubernetes-native, declarative API, allowing Zipline to describe their infrastructure's desired state in a familiar language, abstracting away complex networking configurations like port channels."
The Zipline cluster started as a collapsed-core design on a modest server footprint and has since grown to over 60 servers across multiple racks in a spine-leaf topology. Through both phases, the operations model has remained the same: the existing software engineering team operates the network using the same Kubernetes-style declarative configuration they use for everything else. There is no dedicated NetOps team for the AI cluster. There are no Ansible playbooks to maintain because the Hedgehog controller continuously reconciles desired state. There is no specialized RoCE tuning headcount because the reference architecture ships with the tuning already encoded.
Zipline's published outcome: a private cloud that cut infrastructure costs by 70% compared to public cloud alternatives, with data kept under their own governance. The critical operational win was not just the hardware savings — it was that the staffing model stayed the same.
This is the operational anchor for understanding what Hedgehog enables. The Zipline case demonstrates, with a named customer and a public presentation, that operating an AI cloud with Hedgehog does not require a specialized network engineering function. The headcount required is the headcount any competent DevOps team already has.
The right comparison is not Hedgehog versus doing nothing. It is Hedgehog versus Ansible-based network automation — the dominant approach for operators who want to automate but don't want to commit to a commercial platform or build their own from scratch. Ansible is well-documented for network automation. Red Hat's official Network Automation course (DO457) covers exactly this scope: writing playbooks to configure switches, validating network state, performing compliance checks, and detecting configuration drift. Cisco's Coursera Ansible for Network Automation specialization adds Jinja2 templating, YAML data structures, and ios_config-style modules.
The Ansible-driven DIY model is legitimate and widely deployed. It is also more expensive to staff than most operators initially budget. Here is the headcount, role by role, with sourced loaded rates.
These are the engineers who run the GPU cluster itself: Slurm or Kubernetes scheduling, node health monitoring, incident response, and on-call rotation. NVIDIA defines this role explicitly in its Professional Services SRE datasheet as an engineer who "helps customers manage and maintain their cluster remotely by assisting with day-to-day operational cluster management." Insight Cloud's December 2025 review of NVIDIA's Senior SRE role at DGX Cloud documents total compensation in the $250K–$400K range for the experienced version of this role.
For a 1,024-GPU multi-tenant cluster with 24×7 on-call coverage, 4 FTE is the minimum — three shifts plus weekend rotation plus PTO coverage. Loaded cost at $300K per engineer = $1.2M annually.
This role exists in both the DIY and Hedgehog cases — the SREs run the GPU cluster, not just the network. Under Hedgehog, this reduces to 2 FTE because the network operations work that would otherwise add load to the SRE team — incident triage for fabric issues, tenant provisioning, fabric debugging — is absorbed by the declarative controller. Zipline demonstrates this: the same engineers who operate the cluster also operate the network, with no extra headcount required.
This is the role most DIY operators underestimate. Even with Ansible automating routine configuration push, substantial manual NetOps work remains:
Diagnosing RoCE congestion. Ansible cannot auto-tune PFC priority classes or ECN thresholds. When DCQCN triggers, a human reads the telemetry, formulates a hypothesis, and adjusts.
Troubleshooting NCCL hangs. Meta's published Llama 3 training paper documents the painstaking process of identifying which rank, on which node, on which switch is responsible for an All-Reduce stall. This is hours-to-days of human work per incident.
Switch failures. Ansible can re-push a configuration to a replacement switch, but it doesn't diagnose which switch is failing, isolate the affected node from the fabric, or re-rail the workload. A human does those steps.
Tenant onboarding. Adding a tenant to a multi-tenant fabric requires VLAN/VRF provisioning, ACL updates, route advertisement changes, and validation. Ansible runs the playbook; a human writes and parameterizes it each time.
PFC storm investigation. Per Cisco Live's AI networking best practices, PFC misconfigurations can cause cascading deadlocks that require human intervention to break.
For 24×7 fabric coverage on a 1,024-GPU multi-tenant cluster, the minimum NetOps headcount is 4 FTE. Loaded compensation is higher than commodity NetOps because of the RoCE/RDMA specialization premium. Per Vitex Tech's 2025 InfiniBand vs Ethernet analysis: "InfiniBand requires specialized network engineering skills that command significant salary premiums and are genuinely scarce in the market." The same applies to RoCE — PFC, ECN, DCQCN, VXLAN EVPN, deadlock prevention are equally specialized skills. Vitex documents a $120,000+ annual specialist premium for production RDMA experience on top of a senior network engineer base ($200–250K), giving a loaded rate of approximately $350K.
4 NetOps × $350K = $1.4M annually. This is the role Hedgehog eliminates entirely. Zipline operates their AI training cluster with zero specialized NetOps engineers.
Someone has to write and maintain the Ansible playbooks. Red Hat's DO457 course describes the role: "network administrators or infrastructure automation engineers who want to use network automation to centrally manage the switches, routers, and other devices in the organization's network infrastructure." The skill mix is Python + Ansible + Jinja2 + CCIE Data Center-level networking knowledge. Sustaining the playbook portfolio for a complex multi-tenant fabric on Spectrum-X or SONiC is a 2 FTE job:
Loaded rate: $300K (base $180–220K + Python/Ansible specialization premium + benefits). Annual cost: $600K.
This role disappears under Hedgehog because the declarative controller replaces the playbook engineering effort. Configuration is expressed as Kubernetes Custom Resource Definitions reconciled continuously by the controller — there are no playbooks to write, version, or debug.
Someone has to swap optics, run cables, and replace failed hardware. This role exists in both DIY and Hedgehog cases — declarative fabric does not replace physical access. Loaded cost reflects the premium for AI data center experience (liquid cooling, high-density 800G optics, fiber management) over commodity DC technicians. Per IEEE Spectrum's January 2026 AI Data Centers Face Skilled Worker Shortage report, AFCOM 2025 data identifies multiskilled DC operators as the top growth area for 58% of data center managers — a genuinely competitive market for AI-experienced technicians.
2 FTE provides business-hours coverage with on-call backup. $300K annually, same for both DIY and Hedgehog.
| Role | DIY FTE | Hedgehog FTE | DIY Annual Cost | Hedgehog Annual Cost |
|---|---|---|---|---|
| Cluster SRE / DevOps | 4 | 2 | $1,200,000 | $600,000 |
| NetOps Engineer (RoCE/Spectrum-X) | 4 | 0 | $1,400,000 | $0 |
| Network Automation Engineer (Ansible) | 2 | 0 | $600,000 | $0 |
| Remote Hands Technician | 2 | 2 | $300,000 | $300,000 |
| Operations Staff Subtotal | 12 | 4 | $3,500,000 | $900,000 |
The staffing picture is stark: 8 fewer engineers, $2.6M less in annual payroll. That $2.6M is real incremental EBITDA — but it is the smallest contributor to the total EBITDA gap between a Hedgehog-based operator and a DIY operator. The larger contributions come from the operational outcomes the staffing model enables.
So why does the operations model matter so much? Because the staffing difference is the mechanism behind the much larger value created in reliability, performance, and security.
The 12-versus-4 headcount gap is not just a payroll comparison. It is the structural cause of the operational differences that compound across every other dimension of the business.
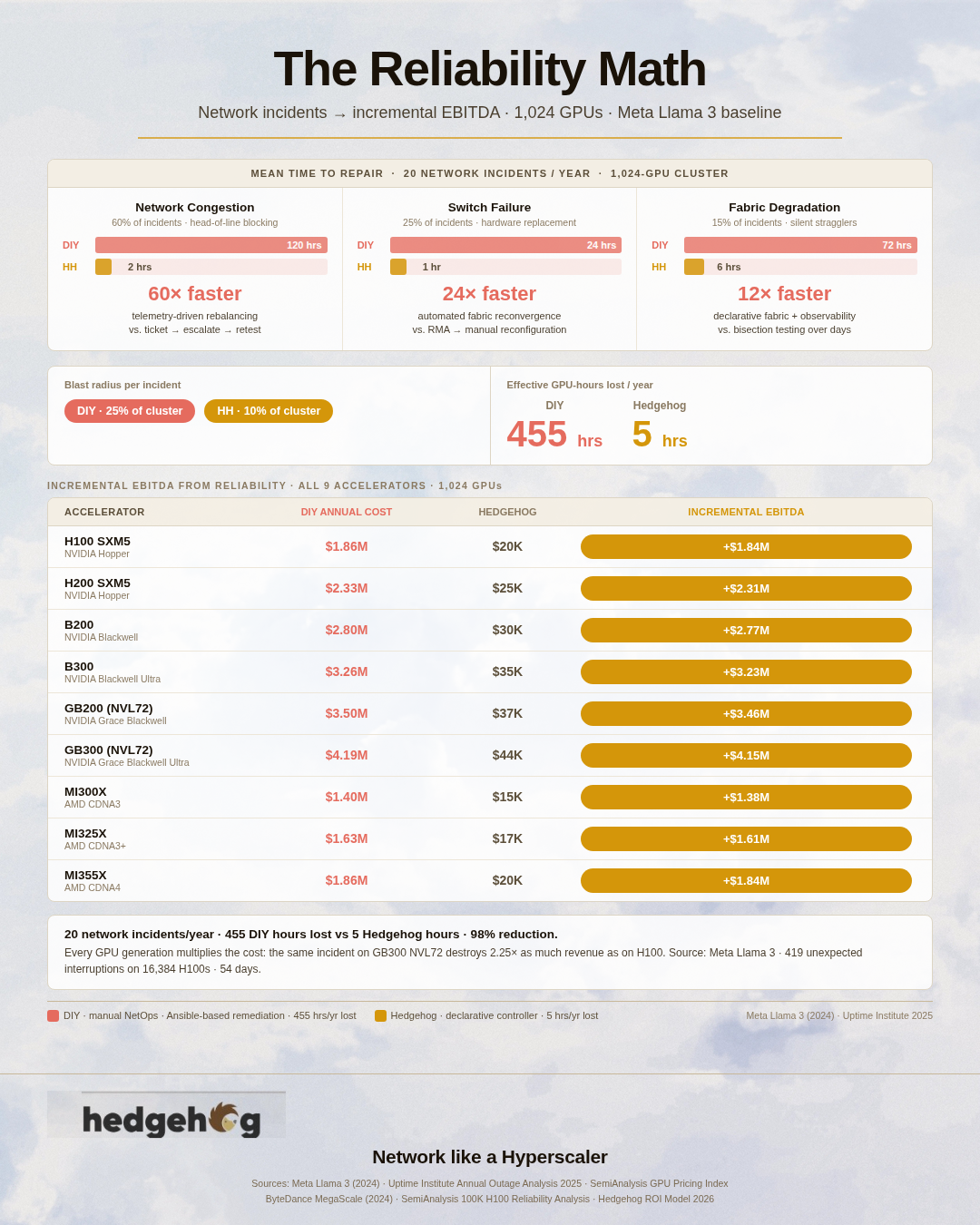
Reliability. A DIY cluster running Ansible-based automation remediates network incidents through a human-triggered workflow: an alert fires, an on-call engineer triages, a playbook runs, the fabric recovers. From detection to resolution, this process typically takes hours. Meta's published Llama 3 training data shows more than 20 network events per year per 1,000 GPUs even on well-operated clusters — at hours of MTTR each, this adds up to hundreds of hours of lost GPU-time annually.
Hedgehog's declarative controller detects and remediates incidents continuously. When the observed fabric state diverges from the desired state, the controller reconciles them — no on-call rotation required. The 4-engineer NetOps team in the DIY model exists largely to do what the controller does automatically in the Hedgehog model. The staffing gap and the MTTR gap are the same fact viewed from two angles.
Performance. Getting a GPU cluster to its rated NCCL efficiency requires correct PFC, ECN, DCQCN, and adaptive routing configuration. In a DIY deployment, the 2 network automation engineers spend significant time deriving, testing, and maintaining this tuning in Ansible playbooks. When configurations drift — which they do, on every production cluster — a NetOps engineer investigates. The result is that DIY clusters routinely operate at 60–80% of their rated NCCL efficiency.
Hedgehog ships with this tuning already encoded in the reference architecture. FarmGPU's published B200 cluster, built on Hedgehog, hit 392/400 GB/s on SemiAnalysis ClusterMAX 2.0 benchmarks — 98% efficiency. The 0-FTE network automation headcount in the Hedgehog model is not a savings on engineers; it is a reflection of the fact that the tuning doesn't need to be re-derived because Hedgehog ships it validated.
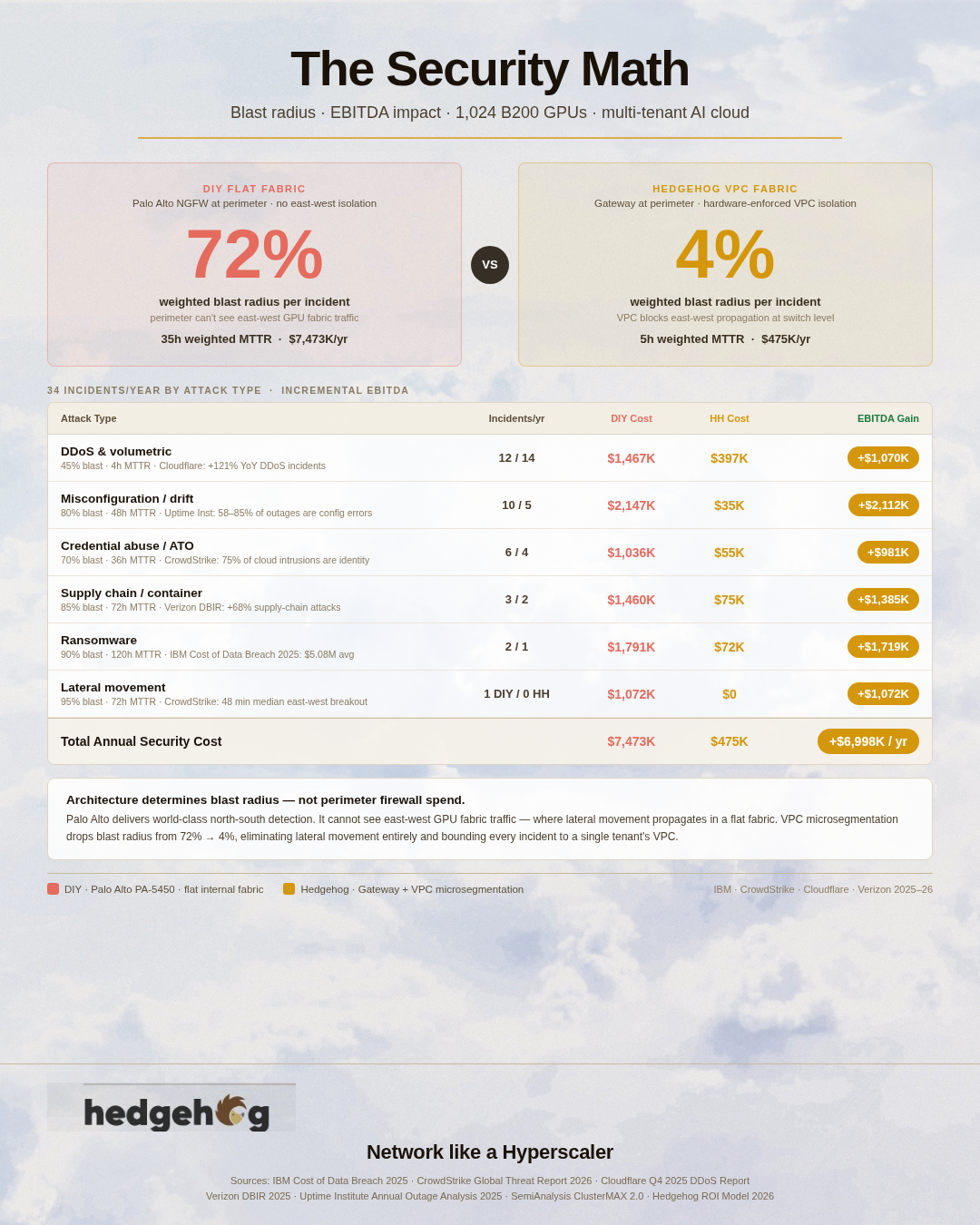
Security. A flat-fabric DIY architecture has no tenant isolation at the network layer. When a security incident occurs — a compromised tenant container attempting lateral movement — the blast radius is the entire shared fabric. The 4 NetOps engineers in the DIY model are partly there to manually contain such events after the fact. Hedgehog's VPC microsegmentation enforces per-tenant isolation in the switch silicon, eliminating the lateral movement vector rather than responding to it. The 0 specialized NetOps engineers in the Hedgehog model is possible partly because there is far less human incident response required when the architecture prevents the incidents.
The framing that matters: the operations headcount in the DIY case is not overhead. It is how the DIY operator pays, in ongoing payroll, for the operational quality that Hedgehog ships as part of the product.
The talent shortage makes the DIY headcount harder to assemble than the dollar figure suggests. Per the Vitex 2025 analysis, RoCE/RDMA specialists are "genuinely scarce in the market" with $120K+ annual premiums. Per Schneider Electric's February 2026 Mind the Gap analysis, "talent may become the primary barrier to scaling AI." Per Second Talent 2026, the global AI infrastructure talent supply-demand ratio is 3.2:1. The DIY model requires 8 specialized engineers in a market where each role takes 3–6 months to fill. Hedgehog's operational model lets a customer staff to "people we can actually hire" rather than "people we theoretically need."
The Zipline case is reproducible, not exceptional. Florian Berchtold is not unusual. He is a competent software engineer using a Kubernetes-native API to manage infrastructure that would otherwise require specialized network knowledge — the same pattern that lets backend engineers run AWS workloads without being network engineers. Hedgehog brings that pattern to on-premises AI networks. The customer profile that benefits is broad: any organization with a competent software or DevOps team that wants to run AI workloads on private infrastructure for cost or governance reasons.
The operations staffing savings are real, but the larger EBITDA contribution is what the staffing model unlocks. The $2.6M payroll difference between 12 DIY engineers and 4 Hedgehog engineers is genuine incremental EBITDA. But the staffing model it represents — software engineers instead of network specialists, a declarative controller instead of an on-call rotation — is what makes the reliability, performance, and security outcomes possible without dedicated headcount to sustain them. A DIY operator can buy better reliability through more NetOps engineers. A Hedgehog operator gets better reliability because the controller that replaces those engineers never goes off-shift. That difference compounds across every dimension of the business, and its full EBITDA impact shows up in the reliability, performance, and security analyses rather than the operations line alone.
Every cluster is different. GPU type, cluster size, operations headcount, workload mix (dense vs. MoE), and target ClusterMAX tier all affect the performance calculation — sometimes significantly. The Hedgehog AI Network Planner (available at plan.hedgehog.cloud) lets you model performance impact alongside several dimensions of AI cloud economics — design, procurement, time-to-GPU-value, operations, performance, reliability, and security — at any cluster size from 64 to 8,192 GPUs.
The model is available as both a web-based wizard and a downloadable Excel workbook with every formula visible and every assumption editable. If your workload mix, utilization assumptions, or target rental tier differ from the defaults used here, the model is built to reflect your actual situation.
1 min read
Hedgehog AI Network Planner: Part 7

1 min read
Hedgehog AI Network Planner: Part 6
1 min read
Hedgehog AI Network Planner: Part 8