
 Marc Austin
Marc Austin
1 min read
The Design Math: Why Reference Architectures Win
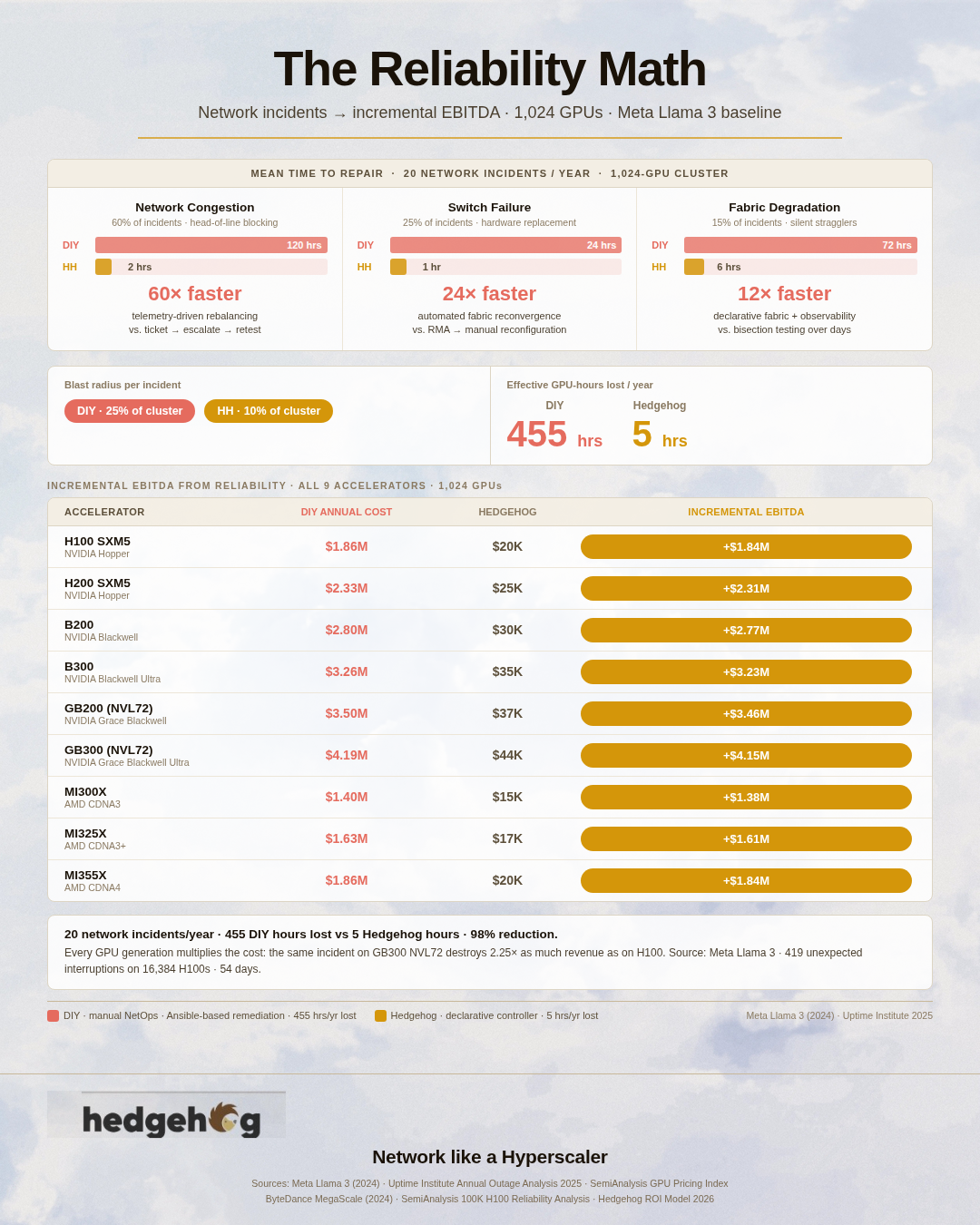
Hedgehog AI Network Planner: Part 1 We recently announced that Hedgehog is an NVIDIA-validated solution architecture for NVIDIA Spectrum-X. We also...

1 min read
Hedgehog AI Network Planner: Part 1 We recently announced that Hedgehog is an NVIDIA-validated solution architecture for NVIDIA Spectrum-X. We also...

1 min read
Hedgehog AI Network Planner: Part 5
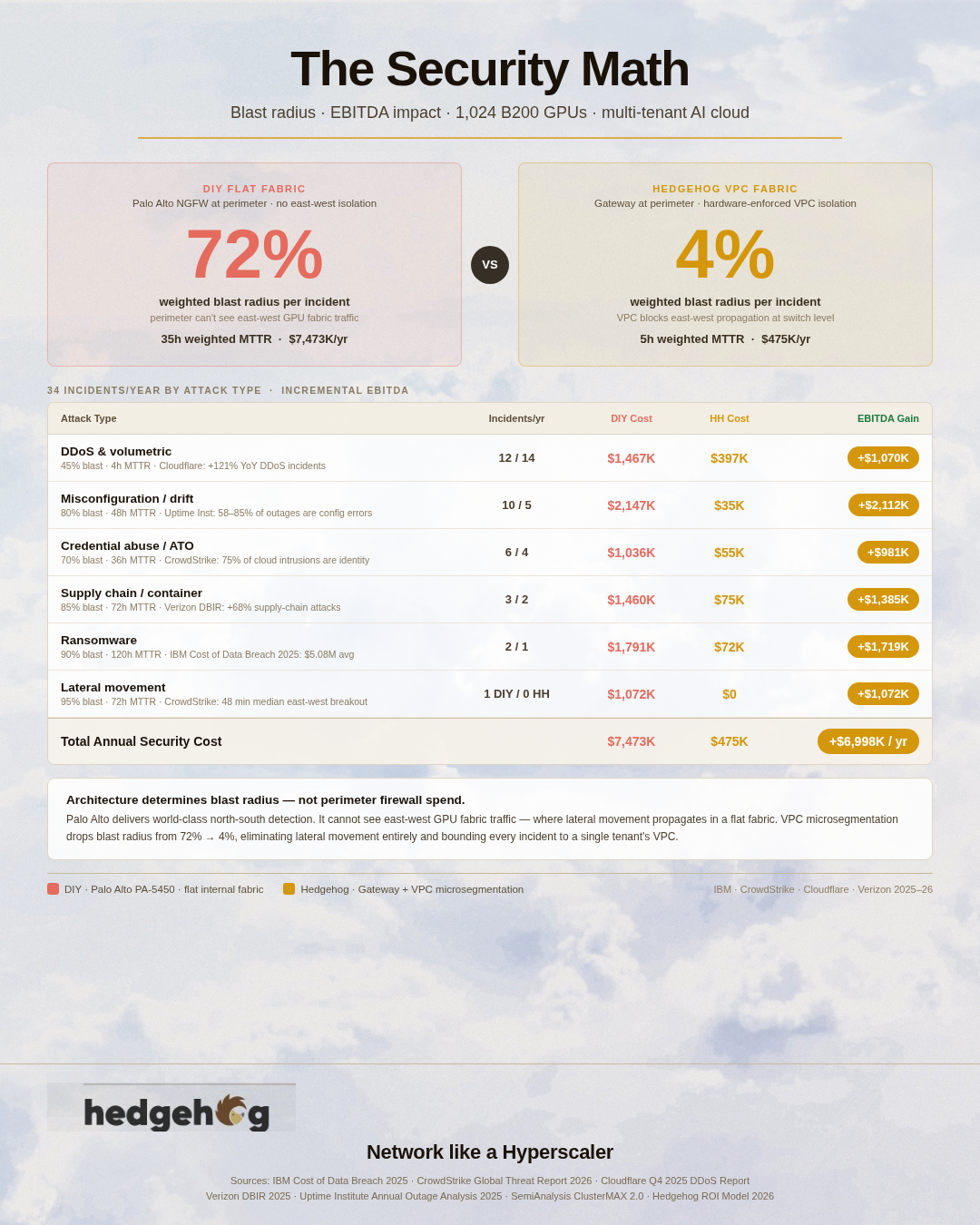
1 min read
Hedgehog AI Network Planner: Part 8