
 Marc Austin
Marc Austin
1 min read
The Design Math: Why Reference Architectures Win
Hedgehog AI Network Planner: Part 1 We recently announced that Hedgehog is an NVIDIA-validated solution architecture for NVIDIA Spectrum-X. We also...
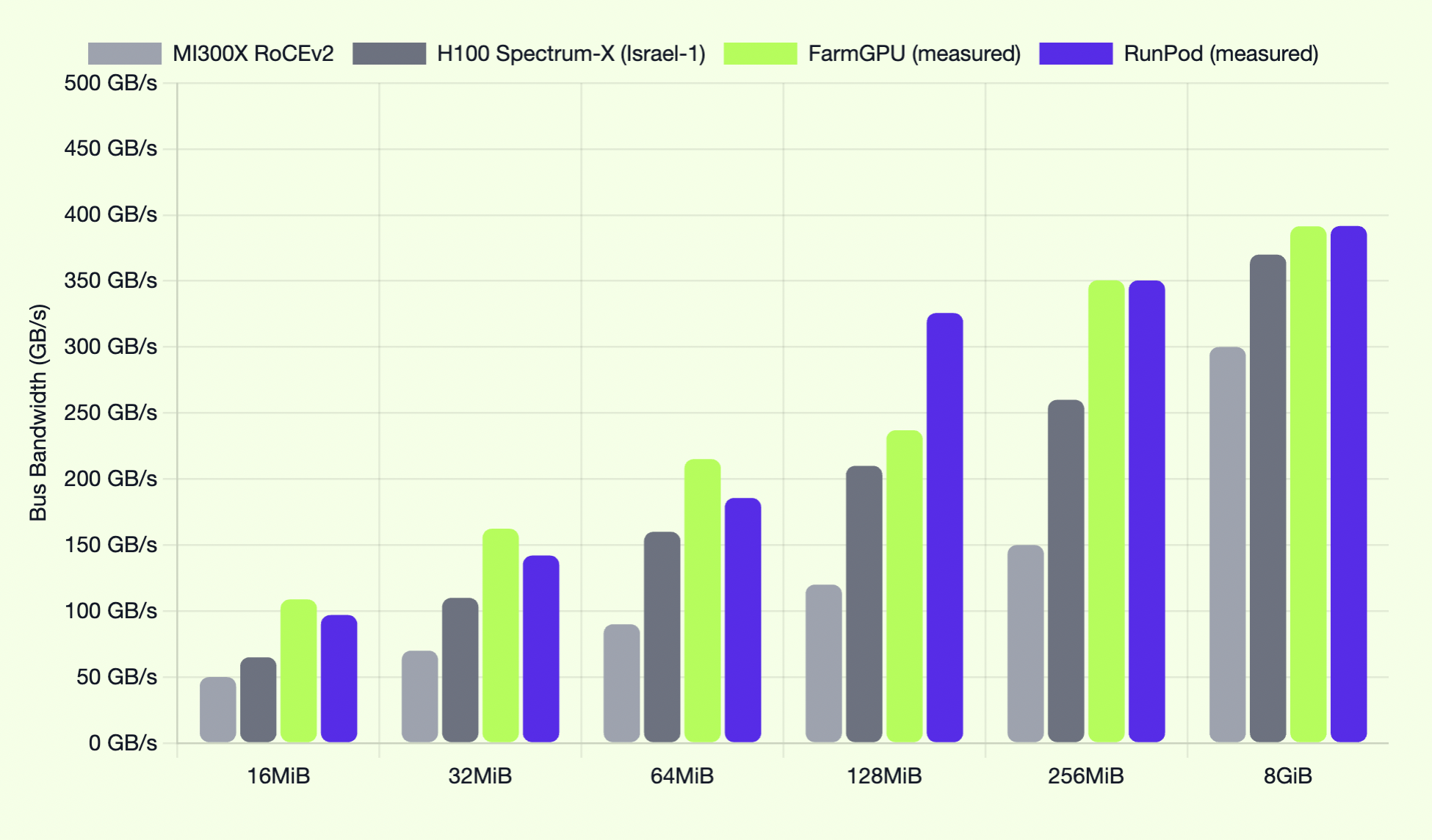
SemiAnalysis recently completed ClusterMAX testing on NVIDIA B200 GPU services offered by FarmGPU and RunPod. NCCL testing of their Hedgehog AI network showed industry leading performance. FarmGPU and RunPod offer better AI network performance than NVIDIA Israel-1, an AMD MI300X cluster running untuned RoCEv2, and even Crusoe Iceland's Infiniband network.

Semi Analysis is an independent analyst that breaks the mold on market research. They don't try to cover every industry. They focus on neoclouds. They don't scheduling briefings to write a lot of subjective content. If you open your doors, they will test your GPU cluster for a number of ClusterMAX rating criteria. Then they will give you a ClusterMAX rating. The intent of all this is to help GPU renters make smart purchase decisions for their AI workloads.
Semi Analysis evaluate features that GPU renters care about, such as:
Hedgehog impacts most of these criteria, but for this report we are focusing on NCCL/RCCL Networking Performance. Hedgehog optimizes NCCL/RCCL networking performance with open source AI networking software that tunes configuration of network switches and SuperNICs running in GPU servers. Our software does this in an automated fashion, so you don't have to spend weeks learning the secret sauce. That means rapid time to value for your very expensive GPU cluster.
GPU renters need to get lots of data in and out of GPU clusters. That requires a high performance network. When they run training workloads, GPUs need to share memory over the network. That means the AI network needs to run at peak performance if you want to get optimal GPU performance.
Here's a snapshot of the FarmGPU AI infrastructure stack. Hedgehog's job is to make it really easy to run an AI network while we squeeze every byte of performance out of the network equipment. And yes, there are a lot of hardware components in the solution architecture.
FarmGPU, Celestica and Hedgehog presented these results together at OCP Global Summit. We also talked about the challenges of getting this to work for fully automated, hyperscale operations. It's not easy. To make it easier for the Open Compute Project community to network like hyperscalers, we committed to contributing this solution as an OCP reference architecture. We'll post again when this is live in the OCP Marketplace.

1 min read
Hedgehog AI Network Planner: Part 1 We recently announced that Hedgehog is an NVIDIA-validated solution architecture for NVIDIA Spectrum-X. We also...

1 min read
In my “AI Needs a New Network” post last week, I noted that NVIDIA reported $13 billion in networking ARR on $18.4 billion of annual data center...
1 min read
Hedgehog AI Network Planner: Part 8