The Design Math
Why Reference Architectures Win
Designing an AI network from scratch is a notoriously complex undertaking. It demands highly specialized network engineering talent—a resource that is both expensive and scarce. When organizations choose the DIY route, they inevitably face months of architecture design, component testing, and troubleshooting. This "build it yourself" approach creates massive engineering overhead and introduces dangerous project delays.
The alternative is leveraging validated reference architectures. By starting with a known-good blueprint tuned specifically for extreme scale, organizations bypass the trial-and-error phase entirely. Hedgehog eliminates the need for specialized network engineering to stand up a cluster. We provide standardized, high-performance designs that allow your team to move straight to deployment, saving months of costly engineering time and drastically reducing initial architectural friction.
The CapEx Math
Unlocking Your GPU Investment
If you look at the total CapEx for an AI cluster, the network components—switches, transceivers, and cabling—are a fraction of the cost compared to the compute hardware. Yet, this smallest line item wields disproportionate power. A sub-optimal network throttles your expensive GPUs, leaving them starved for data and idling during critical training runs. Every moment a GPU waits for data is a sunk cost.
By investing strategically in a high-performance network fabric managed by Hedgehog, you ensure that your compute resources operate at peak capacity. You aren’t just buying switches; you are buying the utilization rate of your entire cluster. Optimizing this minor CapEx investment guarantees that the massive capital spent on GPUs actually delivers the promised compute cycles, ensuring maximum yield on your hardware investments.
The Sell Math
How ClusterMAX 2.0 Ratings Translate Into Revenue
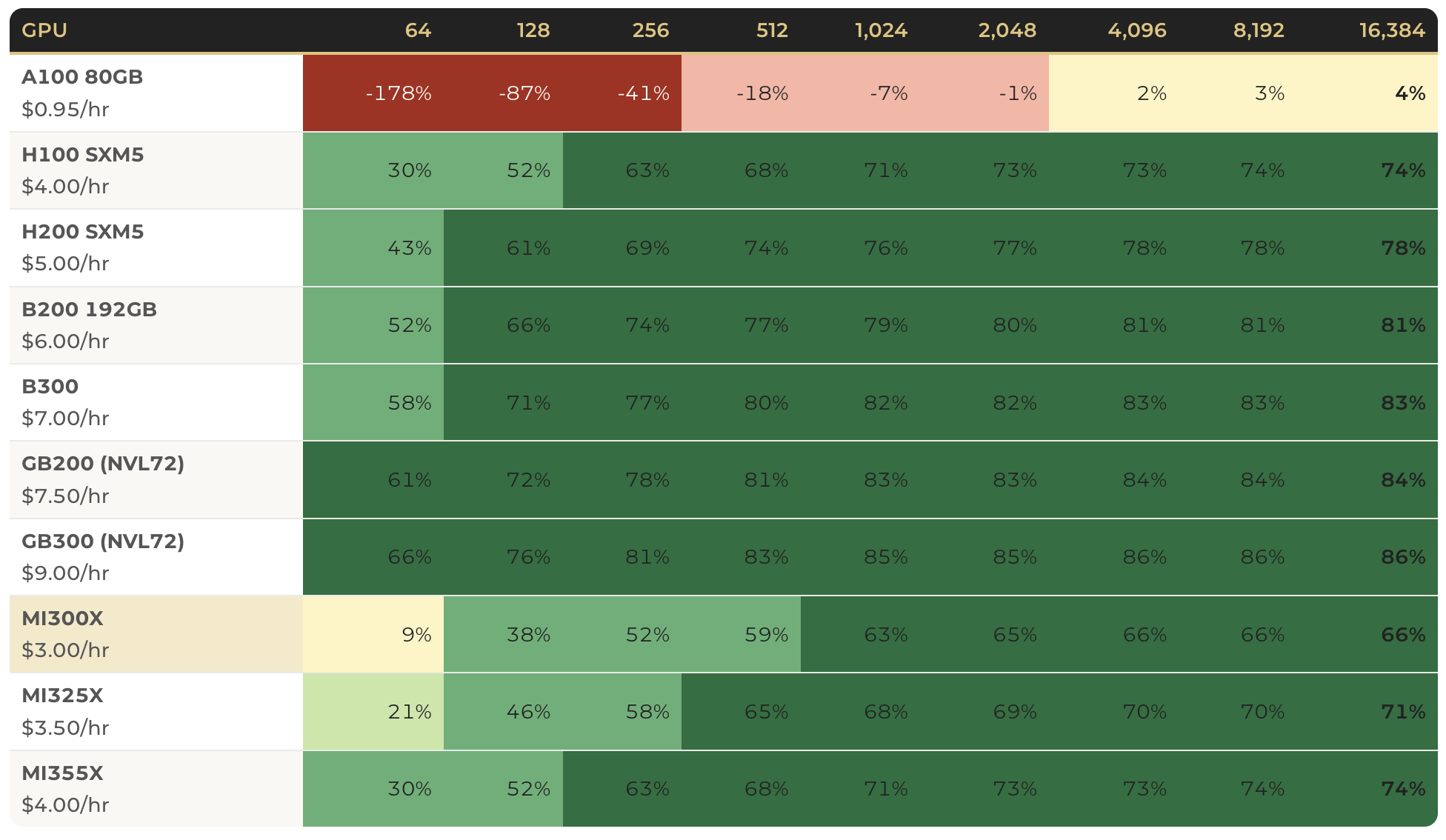
For AI cloud providers, cluster performance is the product. Customers benchmark networks aggressively, and metrics like the ClusterMax 2.0 rating have become the industry standard for evaluating the true throughput and efficiency of an AI environment. A higher ClusterMax score directly correlates to faster training times and higher inference tokens per second.
Hedgehog’s precise traffic management and automated optimization ensure your fabric consistently hits the highest possible performance benchmarks. By eliminating bottlenecks and optimizing complex traffic flows under the hood, Hedgehog allows you to sell premium, high-tier compute access. When your cluster performs better than the competition, you can command higher prices, attract top-tier AI developers, and directly translate your network’s efficiency into tangible top-line revenue growth.

The Speed Math
The Value of Zero-Touch Provisioning
In the AI race, time is directly correlated with market share and revenue. Getting a cluster racked, stacked, and cabled is only half the battle. The true milestone is "Time-to-GPU-Value"—the moment those processors actually start running workloads. Manual network configuration is a tedious, error-prone process that acts as a massive roadblock to revenue generation.
Hedgehog accelerates this timeline through Zero-Touch Provisioning (ZTP). By automating the deployment process based on proven reference architectures, Hedgehog turns what used to be weeks of manual CLI configuration into a seamless, automated workflow. This zero-friction approach eliminates configuration drift and ensures that the network is perfectly tuned from day one. Shaving weeks off your deployment schedule means you can bring AI products to market faster and start recognizing ROI significantly sooner.

The Operations Math
Empowering Standard DevOps
Operating an AI network typically requires a dedicated team of specialized network engineers to manage state, monitor traffic flows, and resolve complex fabric issues. This introduces significant operational expenditure (OpEx) and creates organizational silos. Hedgehog fundamentally alters this operations math by shifting network management into the realm of standard DevOps.
Through open observability, automated state optimization, and intent-based management, Hedgehog abstracts away the hyperscale engineering complexity. Your existing DevOps teams can manage the AI network using the same tools and workflows they use for the rest of your infrastructure. This democratization of network operations drastically lowers your OpEx, reduces the need for expensive specialty hires, and creates a more agile, unified engineering culture.

The Performance Math
Unlocking Millions in Compute Yield
When deploying next-generation hardware like NVIDIA B200 GPUs, the sheer volume of data required to keep them saturated pushes traditional networks past their breaking point. The performance math is simple but staggering: even a marginal increase in fabric speed and congestion management can yield millions of dollars in reclaimed compute time. By eliminating microbursts and optimizing routing at the ASIC level, Hedgehog ensures that your high-end clusters operate without latency bottlenecks. For a standard B200 cluster, this relentless focus on fabric performance doesn't just improve training times—it translates directly into massive financial returns, effectively adding millions of dollars in equivalent compute value back to your bottom line every single year.

The Reliability Math
The Real Cost of Network Disruption
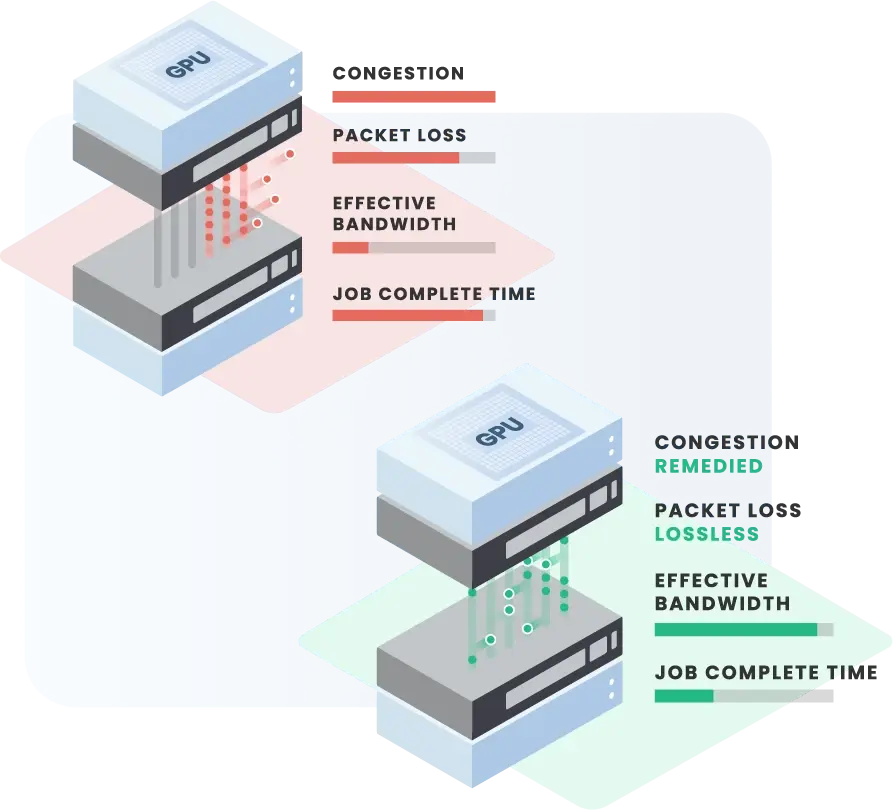
Network downtime in an AI cluster isn't just an inconvenience; it is a profound financial drain. When a training job fails or is paused due to network instability, the cost is measured in lost compute hours, delayed product releases, and wasted energy. The reliability math reveals that even minor network incidents can cost an AI cloud provider millions of dollars annually.
Hedgehog changes this equation by maintaining perfect state optimization and leveraging proven network recipes that guarantee stability. The automated fabric continuously monitors for anomalies and adjusts dynamically to prevent congestion or hardware failures from impacting workloads. By ensuring your GPUs are always fed and your cluster remains highly available, Hedgehog eliminates the hidden, crippling costs of network unreliability.

The Security Math
Shrinking the Blast Radius
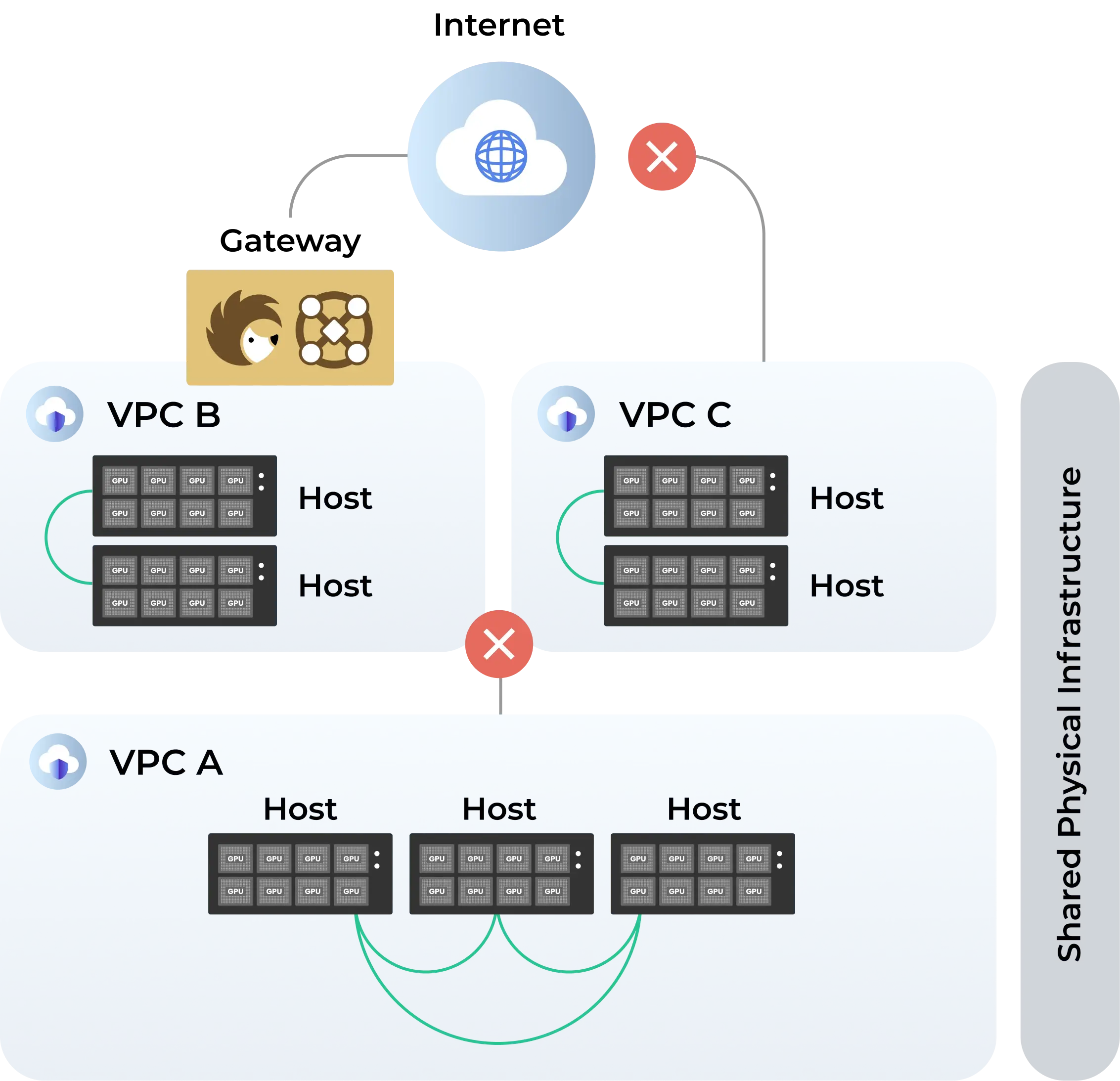
As AI clouds increasingly adopt multi-tenant architectures to maximize utilization, security becomes an existential concern. A single misconfiguration or breach in a shared GPU environment can compromise multiple customers, leading to catastrophic reputational damage and financial liability.
The security math demands a network designed to enforce strict isolation without compromising the high-bandwidth, low-latency performance required by AI workloads. Hedgehog integrates robust security protocols directly into the fabric, creating isolated tenant environments that drastically minimize the blast radius of any potential incident. By ensuring that traffic is securely segmented and monitored continuously, Hedgehog provides cloud operators and their customers with the peace of mind required to run mission-critical AI workloads in a shared infrastructure environment.
Calculate your AI Network Value
The mathematical reality of AI networking is clear: the infrastructure you choose defines your ultimate success. From the initial CapEx investment to the ongoing OpEx of management, security, and reliability, a purpose-built AI fabric is the highest-leverage asset in your data center. Hedgehog provides the seamless deployment, automated operations, and proven performance necessary to maximize the return on your AI hardware investments.
Ready to see the exact numbers for your infrastructure? Calculate your savings and revenue impact with the Hedgehog ROI Calculator today.