
 Marc Austin
Marc Austin
1 min read
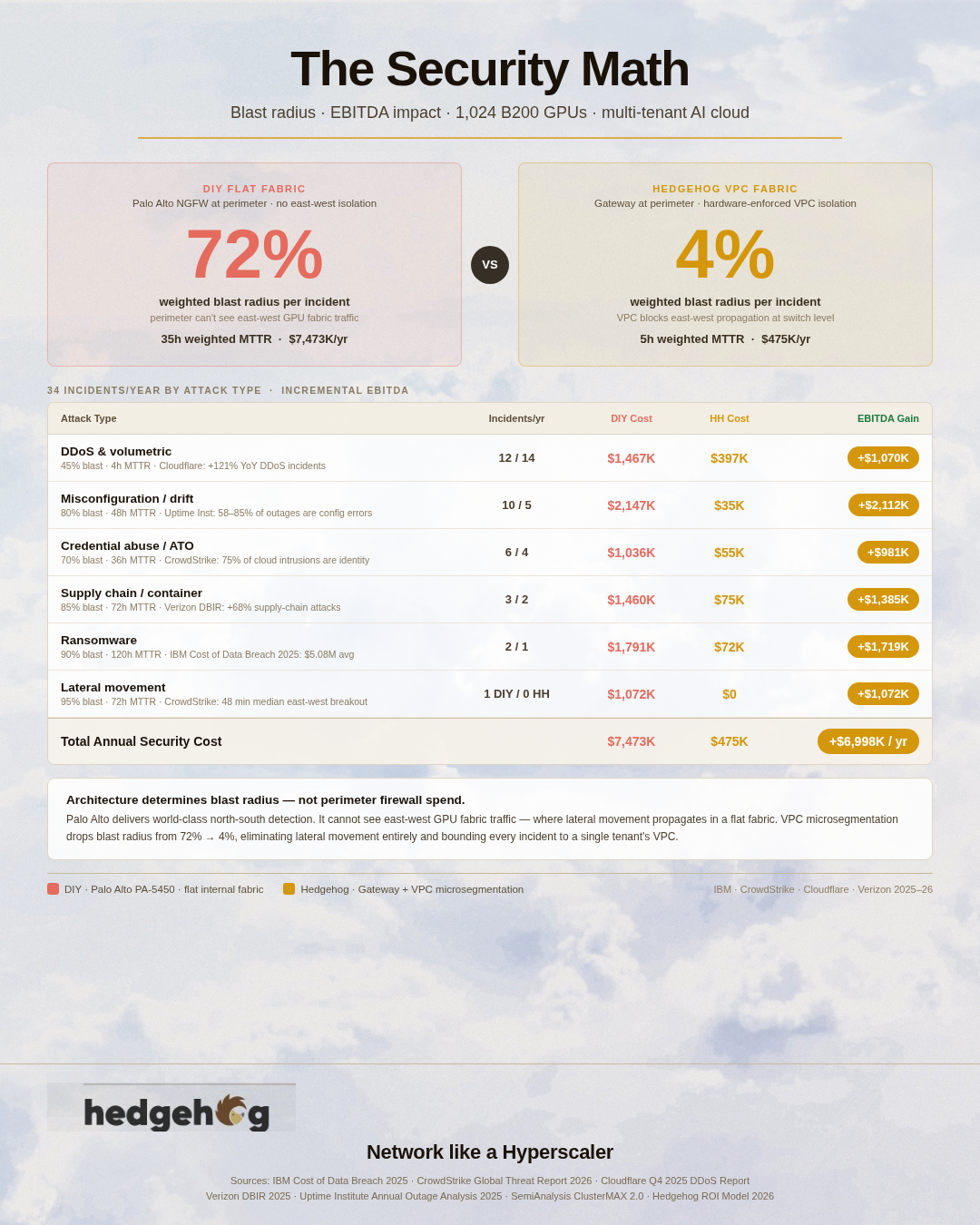
The Security Math: Shrinking the Blast Radius
Hedgehog AI Network Planner: Part 8

Hedgehog AI Network Planner: Part 1
We recently announced that Hedgehog is an NVIDIA-validated solution architecture for NVIDIA Spectrum-X. We also announced that the Open Compute Project community accepted Hedgehog contribution for OCP AI network reference architectures. What the heck is a reference architecture and why do I need one? Why can’t I just design my own AI network?
The OCP RAs offer out-of-the-box designs for up to 1024 xPUs. Hedgehog is validated to operate Spectrum-X networks for much larger clusters of GPus. Designing this stuff is not easy. It requires specialized skills and time if you want to do it from scratch.
Real AI fabric design at this scale requires five specialist roles working in parallel for 4–5 months of calendar time, plus 2–3 months of senior architect recruiting lead time, totaling around $534,000 in design labor and 6 months of elapsed time before a single GPU starts earning revenue. That gap — between an optimistic project plan and the painful real one — is what NVIDIA's Spectrum-X reference architecture, Hedgehog's OCP-contributed reference architectures, and the broader OCP Strategic Initiative Open Cluster Designs exist to close.
This post walks through exactly what AI fabric design entails today, what skills it requires, what those skills cost in the 2026 market, and what AI cloud builders save by deploying a validated AI network reference architecture instead of designing one from scratch.
Spectrum-X is not a switch. It is an integrated platform with a substantial design surface, and that surface has grown with each generation. NVIDIA's published Spectrum-X reference architecture define the components and topology constraints, but every operator deploying Spectrum-X must still make scores of design decisions specific to their cluster size, tenant model, storage stack, and security posture.
The HGX B300 Spectrum Enterprise RA for a 32-server / 256-GPU scalable unit specifies:
For a 1,024-GPU cluster (8 scalable units), the BOM scales to roughly 64 leaf switches plus a spine tier, hundreds of optical transceivers, and an entire fabric of cables that must be wired according to the rail-optimization scheme. Get the cabling wrong and NCCL collective operations lose 30–40% of their throughput — which, as we will show in a performance blog post, translates to $5.4M in lost annual revenue on a 1024 B200 cluster.
Beyond the physical fabric, an AI network design must also address:
Each of these areas has documented best practices in the NVIDIA Spectrum-X deployment guide and the Hedgehog OCP white papers, but the practices have to be applied to the specific cluster being built. That application is the design phase.
An AI fabric design is not a one-person job. Across dozens of recent production AI cloud deployments, the skill matrix consistently breaks into five distinct specialist roles, and the labor market treats them as such:
The architect owns the topology, scales the BOM, sizes bisection bandwidth, and reconciles the customer's tenant model with the underlying physical fabric. This is a 4+ years experience role per Introl's 2025 NVIDIA certification skill matrix, with base salary range $250K–$400K in 2026 (Introl/NVIDIA cert framework; AI infrastructure salaries rose 20–30% between Q1 2025 and Q1 2026 per KORE1).
Loaded with benefits, overhead, and recruiting cost (2x–2.5x base), the effective hourly rate runs ~$400. For a 1,024-GPU design, expect 3 months full-time of lead architect time: 525 hours, $210,000 in labor.
The RDMA specialist tunes RoCEv2 parameters (PFC priorities, ECN thresholds, buffer allocation), validates the storage path against GPUDirect Storage requirements, and aligns the storage fabric topology with the compute fabric. This role increasingly demands NCP-AIN (NVIDIA Certified Professional — AI Networking) certification, which NVIDIA launched in 2025 specifically to validate "deep expertise in InfiniBand, Spectrum-X Ethernet, Remote Direct Memory Access (RDMA), and network fabric optimization for multi-GPU clusters."
Per Introl's 2025 framework, Level 4 base compensation runs $175K–$250K; loaded rate ~$300/hr. Expect 2 months of RDMA specialist time: 350 hours, $105,000.
The security architect maps the network design to the customer's compliance posture: SOC 2 Type II evidence, ISO 27001 control mapping, PCI DSS or HIPAA where applicable, tenant isolation requirements, perimeter NGFW integration, and incident response playbook design. As the security blog in this series will show, this role is increasingly the gate on enterprise customer acquisition. Expect 1 month of security architect time: 175 hours, $52,500.
Whoever builds the actual configuration templates — whether in Cumulus NVUE for Spectrum-X, SONiC config_db YAMLs, or Hedgehog-style declarative Kubernetes CRDs — needs deep platform familiarity, GitOps fluency, and the patience to debug optics initialization bugs at 2 AM. The FarmGPU "17-day crash course" blog post catalogues the kinds of issues that surface in this layer.
Level 3 (1–2 years) base compensation: $125K–$175K; loaded rate ~$250/hr. Expect 2 months of automation engineer time: 350 hours, $87,500.
The validation engineer runs nccl-tests, ib_write_bw, ib_write_lat, MLPerf training proxies, and DCGM Level 3 diagnostics across the new fabric. They flag any link that fails to hit the SemiAnalysis ClusterMAX reference numbers, identify miswiring at scale, and iterate with the automation engineer until the fabric is benchmark-clean. As the performance blog shows, this role is what stands between an AI cloud rating Bronze and rating Silver on ClusterMAX 2.0. Expect 1.5 months: 262 hours, $78,600.
|
Role |
Hours |
Loaded Rate |
Cost |
|
Lead Network Architect (Level 5) |
525 |
$400/hr |
$210,000 |
|
RDMA / Storage Specialist (Level 4) |
350 |
$300/hr |
$105,000 |
|
Security Architect (Level 4) |
175 |
$300/hr |
$52,500 |
|
Automation / SONiC Engineer (Level 3) |
350 |
$250/hr |
$87,500 |
|
Validation / Performance Engineer (Level 4) |
262 |
$300/hr |
$78,600 |
|
Total |
1,662 |
$321/hr blended |
$533,600 |
This is 9.5 person-months of specialist labor, executed across ~5 calendar months on the critical path. The cluster sits in inventory while design completes — and worse, it sits in the procurement queue while the lead architect is being recruited.
Money is not the only cost. Time is.
Per KORE1's 2026 AI Infrastructure Staffing Guide, AI infrastructure salaries rose 20–30% between Q1 2025 and Q1 2026 at the senior level. The same guide notes that AI infrastructure searches that don't produce qualified candidates by week 4 are unlikely to fill at all without a staffing partner. Industry recruiting timelines for senior AI infrastructure roles average 2–3 months minimum, with senior platform engineering roles routinely stretching beyond that. Geographic mismatch is the single biggest constraint — Northern Virginia, the Bay Area, and Seattle have the deepest talent pools, but new AI data centers are being built in Phoenix, Dallas, central Ohio, and rural Oregon where engineers don't already live. Relocation packages run $15,000 to $40,000 per engineer.
Cudo Compute's In-house vs. External Experts analysis from July 2025 quantified the broader picture: 44% of executives cite a shortage of in-house AI expertise as the top blocker to scaling generative AI infrastructure. The Metaintro / AFCOM 2025 State of the Data Center Report estimates 340,000 AI data center roles are currently unfilled due to the skills shortage. NVIDIA's response — the NCA-AIIO, NCP-AIN, and Level 4/5 expert certifications launched between 2024 and 2026 — is a structured attempt to address the gap, but a certification program does not produce experienced architects overnight.
For an AI cloud builder, this translates to a concrete delay: start the recruiting process now, expect a qualified lead architect to be billable in 60–90 days, then start the 5-month design clock. By the time the network is ready for GPUs, more than two quarters have elapsed. In a market where B200 GPUs depreciate at roughly $1,000 per GPU per month, that delay alone costs ~$6M per quarter in carrying cost on a 1,024-GPU cluster — separate from any deployment opportunity cost.
This is also why every reasonable AI cloud builder eventually asks the right question: why are we designing this from scratch?
NVIDIA and Hedgehog both publish AI network reference architectures precisely because the design effort described above is not a moat — it's a tax. Every operator paying that tax ends up at roughly the same answer, with roughly the same wiring scheme, roughly the same QoS parameters, and roughly the same multi-tenant model. The differentiation in AI cloud economics is not in inventing a unique fabric topology; it is in efficiently deploying a known-good one.
NVIDIA publishes the HGX B300 Spectrum Enterprise Reference Architecture through their documentation portal, supplemented by:
This material does ~70% of the design work for a buyer committing to the full Spectrum-X stack (Spectrum-4 switches, BlueField-3 or ConnectX-7 SuperNICs, Cumulus Linux). The buyer still has to customize for their specific tenant model, security posture, storage stack, and DC layout — but they're starting from a validated baseline, not from a whiteboard.
Hedgehog closes this gap with an NVIDIA validated Hedgehog AI network platform that runs on NVIDIA Air digital twin environment for simulation and testing before physical deployment. Hedgehog support for Spectrum-X means that configuration details are automated out of the box for rapid time to NVIDIA GPU value.
In April 2026, Hedgehog contributed its AI Training Fabric and AI Inference Fabric reference architectures to the Open Compute Project, achieving OCP Accepted™ status. Both designs are now available in the OCP Marketplace with complete BOMs, validated production deployment history (at FarmGPU, RunPod, and other Hedgehog customers), and explicit interoperability across silicon vendors to prevent hardware lock-in.
The Hedgehog OCP architectures cover:
For an AI cloud builder, the Hedgehog OCP path replaces 5 months of multi-specialist design with ~1 week of validation and customization by a single architect: confirm the published BOM matches the procurement plan, adjust for site-specific power and cooling constraints, and let the declarative fabric controller handle the rest.
For a Hedgehog deployment based on either the NVIDIA-validated Spectrum-X reference architecture or the OCP-contributed Hedgehog reference architectures, the design phase looks fundamentally different:
|
Activity |
Effort |
|
Validate reference architecture fits site BOM |
1 architect × 1 week |
|
Customize for tenant model and security posture |
Built into Hedgehog declarative config |
|
Day 0/1/2 automation |
Provided by Hedgehog control plane |
|
NCCL validation |
Reference numbers published; spot-check sufficient |
|
Total |
~80 hours × $400/hr ≈ $17,500 |
The Hedgehog architecture absorbs the design effort because the reference architecture, the BOM, the automation stack, and the validated production deployment history all ship as a single product. The customer is not re-inventing the fabric; they are configuring a known-good one for their specific cluster.
The Design section of the Hedgehog AI Cloud Business Planning Playbook models the financial impact of choosing a DIY design with these default values. Feel free to change the assumptions for your own DIY plan.
|
Assumption |
Model Value |
Source |
|
Architect hourly rate (DIY) |
$321/hr blended across 5 roles |
Introl 2025 NVIDIA certification framework + KORE1 2026 AI Infrastructure Staffing Guide |
|
Design calendar time (DIY) |
5 months (critical path) |
NVIDIA Spectrum-X HGX B300 Enterprise RA documentation effort + bottom-up role estimate |
|
Design team size (DIY) |
1.9 FTE average concurrent |
9.5 person-months across 5 specialist roles |
|
Total DIY design expense |
$533,662 |
1,662 hours of specialist labor at blended rate |
|
Architect hourly rate (Hedgehog) |
$400/hr |
Single Level 5 architect validating reference architecture fit |
|
Design calendar time (Hedgehog) |
0.25 months (1 week) |
OCP reference architecture or Spectrum-X RA validation |
|
Total Hedgehog design expense |
$17,500 |
80 hours at $400/hr |
|
Design phase savings |
$516,162 |
Three takeaways.
A 256-GPU cluster requires roughly the same five specialist roles as a 4,096-GPU cluster — the topology is bigger but the design categories are identical. This means the relative cost of designing from scratch grows worse as clusters shrink. For a 256-GPU pilot deployment, $534K of design labor against ~$10M of GPU spend is 5% of capex before the first packet has flowed. For a 4,096-GPU deployment, the same effort is closer to 1% of capex. Reference architectures benefit small clusters even more than large ones.
When 44% of executives report AI expertise shortage as their top scaling blocker, and recruiting lead times for senior AI architects run 60–90 days minimum at compensation that has moved 20–30% in the last year, the option of hiring an internal team to do the design is increasingly a 6–9 month decision — not a 2-month one. Reference architectures don't just save labor cost; they collapse the calendar time to billable GPUs by eliminating the recruiting dependency.
Every neocloud running B200 clusters on Spectrum-X is converging on the same fabric design, because there is one right answer for non-blocking rail-optimized dual-plane Ethernet. Where AI clouds actually differentiate is in multi-tenancy posture, customer experience, ClusterMAX rating, and pricing. Design effort spent re-deriving NVIDIA's published reference architecture is design effort not spent on the things customers actually choose between. Hedgehog's OCP contribution removes the temptation to redo settled work.
Every cluster is different. GPU type, cluster size, workload mix (dense vs. MoE), and target ClusterMAX tier all affect the performance revenue calculation — sometimes significantly. The Hedgehog AI Network Planner (available at plan.hedgehog.cloud) lets you model performance impact alongside several dimensions of AI cloud economics — design, procurement, time-to-GPU-value, operations, performance, reliability, and security — at any cluster size from 64 to 8,192 GPUs.
The model is available as both a web-based wizard and a downloadable Excel workbook with every formula visible and every assumption editable. If your workload mix, utilization assumptions, or target rental tier differ from the defaults used here, the model is built to reflect your actual situation.
1 min read
Hedgehog AI Network Planner: Part 8
1 min read
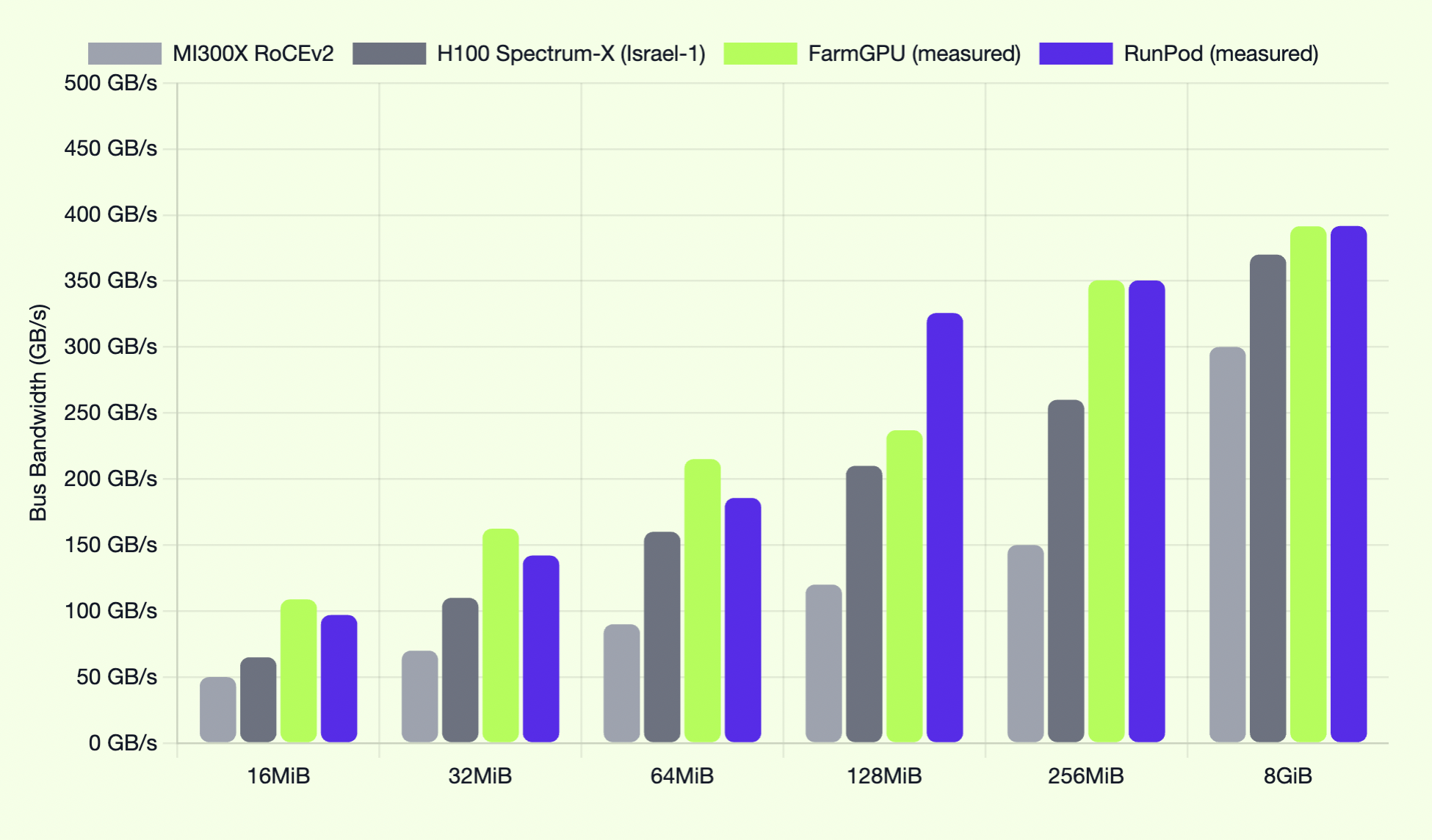
SemiAnalysis recently completed ClusterMAX testing on NVIDIA B200 GPU services offered by FarmGPU and RunPod. NCCL testing of their Hedgehog AI...
1 min read
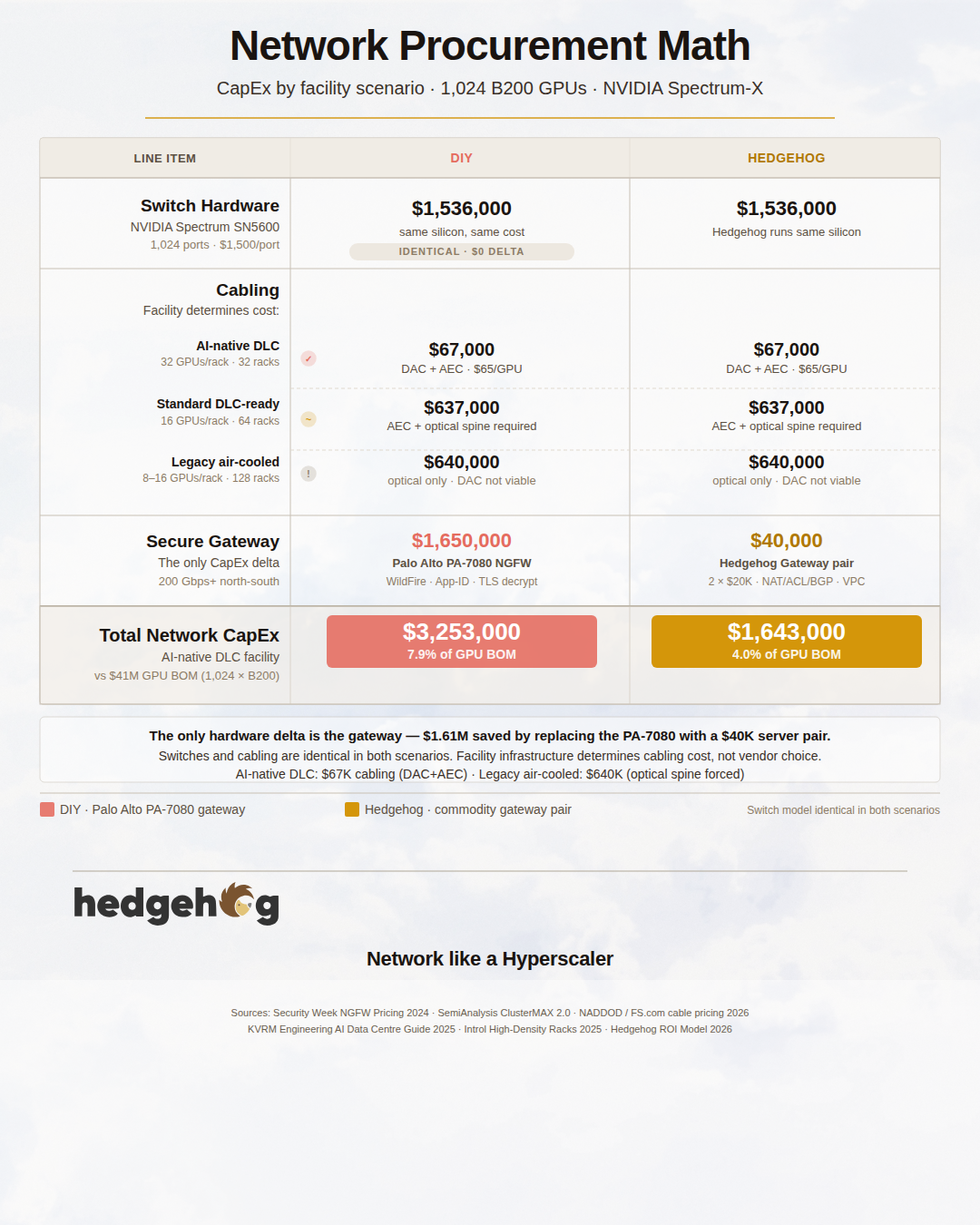
Hedgehog AI Network Planner: Part 2 When teams build AI clusters, the budget conversation almost always starts and ends with GPUs. That is rational....