
 Marc Austin
Marc Austin
1 min read
The AI Networking Revolution: Dawn of a New Epoch
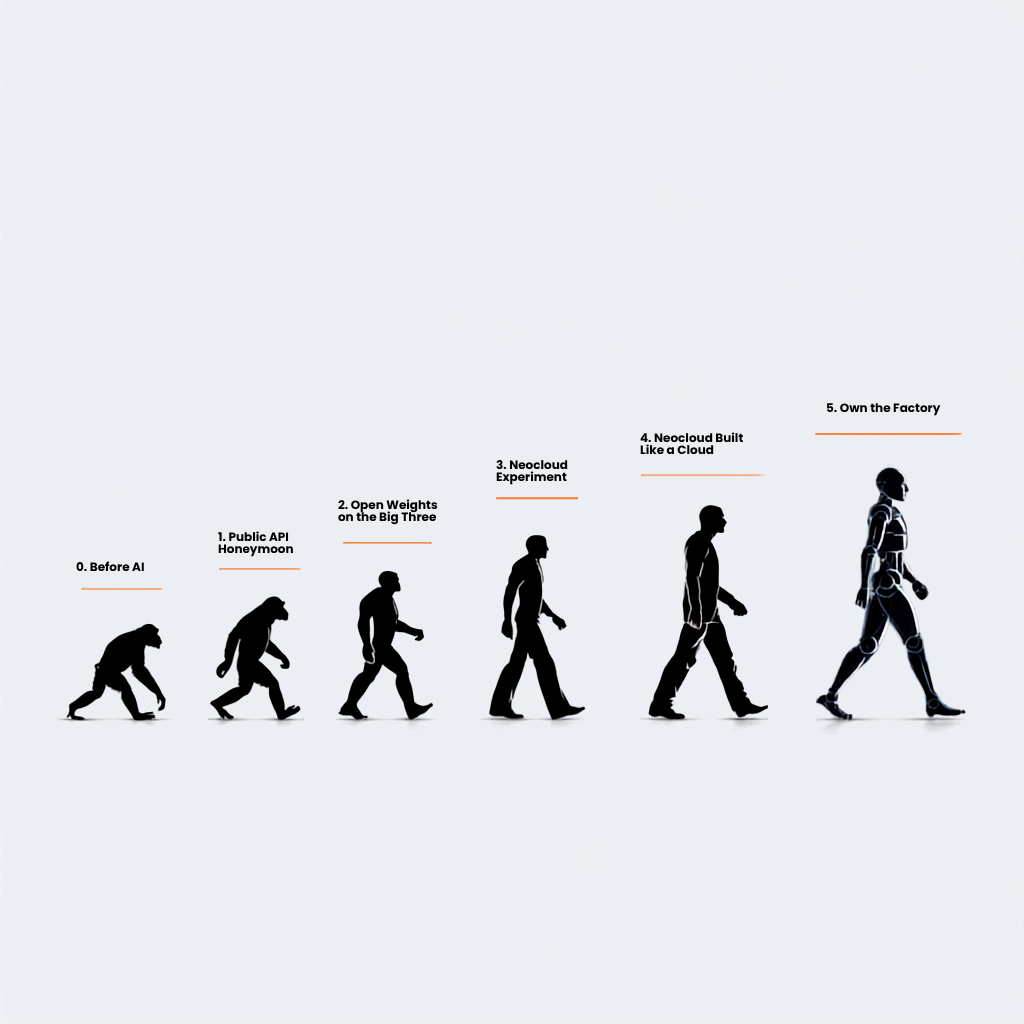
When we look back at the history of networking, it's clear that the industry moves in distinct epochs. These technological eras aren't merely defined...

1 min read
When we look back at the history of networking, it's clear that the industry moves in distinct epochs. These technological eras aren't merely defined...

1 min read
The same AI model can require significant differences in infrastructure depending on whether you're training it or running it. Here's why your...

1 min read
Dell'Oro Group just released their 4Q 2024 Ethernet Switch - Data Center Report showing record-breaking sales fueled by AI buildouts and a recovery...